什么是声音
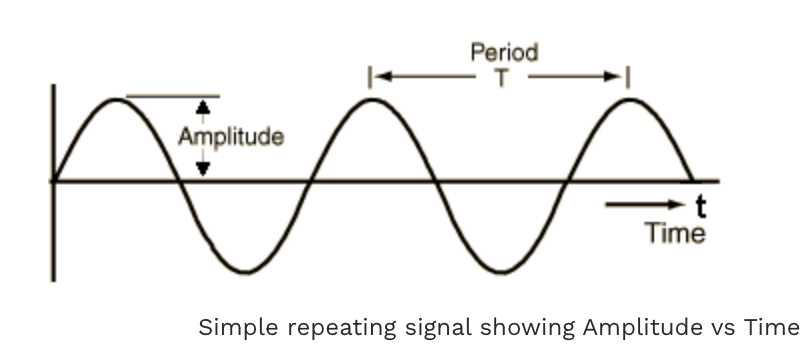
我们从中学学到的那点东西知道声音信号是气压变化产生的。我们可以测量压力变化的强度,并绘制这些测量值随时间的变化图。声音信号通常以固定的时间重复,以便每个波有固定形状(自行脑补简谐振动波形图)
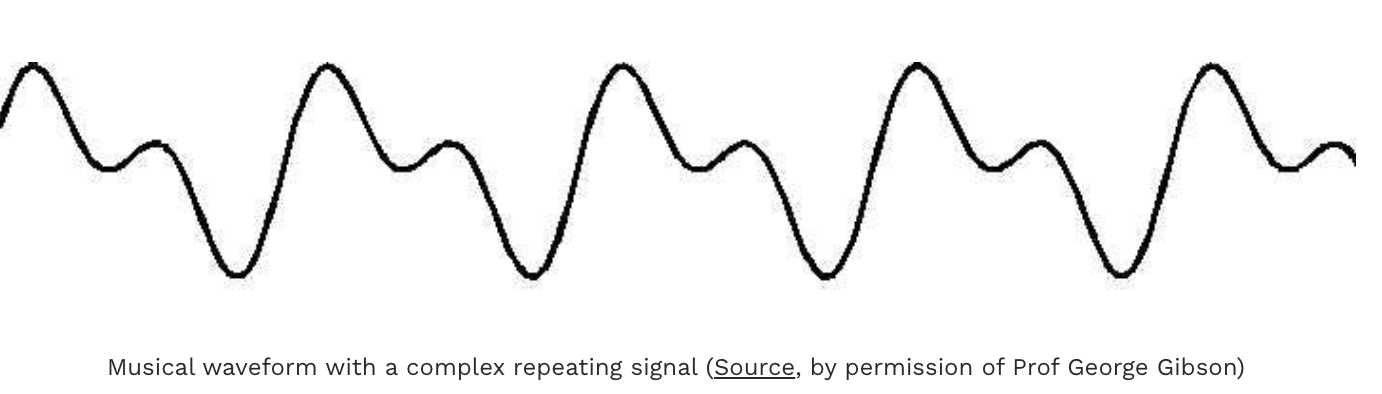
我们遇到的大部分声音不遵循这种简单且规律的周期性模式,但是可以把不同频率的声音叠加,得到更复杂更奇怪的声音复合信号。我们听到的任何声音包括人声,都可以由这种波形组成。
例如,下面这个东西可能是某乐器的声音。
音频学习的“前世今生”
直到几年前,深度学习出来之前,音频学习依赖传统的数字信号处理技术来提取特征。例如,为了理解人类语言,音频信号可以被语言学概念分析来提取音位等元素。但是这些都需要大量的专业领域知识来支撑以获得更好的效果。
近年来随着深度学习越来越普遍,音频的学习也取得进步,通过深度学习,不再需要传统的数字信号处理技术,可以依赖标准的数据准备而无需大量的手动和自定义生成功能。
事实上深度学习处理的不是原始形式的音频数据,而是将音频转换成图像,再用标准的CNN架构来处理这些图像。这些图像是音频生成频谱并进行一些处理得来的。
频谱
我们可以将不同频率的信号相加来创建复合信号,代表现实世界可以出现的任何一种声音。也就是说,任何信号都由不同的频率组成,并且可以表示为这些频率的总和。
频谱就是组合在一起以产生信号的频率集。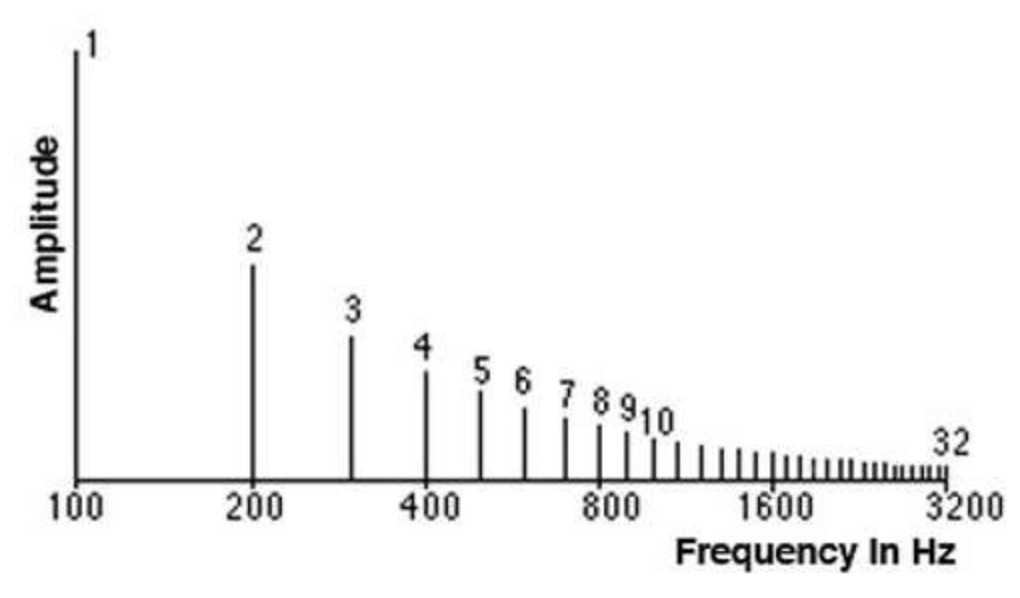
频谱绘制信号中含有所有的频率以及每个频率的幅度等。
信号中的最低频率称为基频,是基频整数倍的频率称为谐波。
时域vs频域
什么是声音开头的图显示的Amplitude versus Time的波形是表示声音信号的一种方式,由于x轴显示了信号的时间值范围,因此我们在时域中查看信号。
频谱则是表示信号的另一种方式,它表示的是Amplitude versus Frequency,这样,x轴显示信号的频率值范围,因此在某个时刻我们在频域中查看信号。
频谱图
由于信号在随时间变化过程中会产生不同的声音,因此其促成频率也会随时间变化,也就是说它的频谱随时间变化。
信号的频谱图绘制了其频谱随时间的变化,就像信号的“照片”。它在 x 轴上绘制 Time,在 y 轴上绘制 Frequency。就好像我们在不同的时间实例一次又一次地获取 Spectrum,然后将它们全部连接成一个图。
它使用不同的颜色来表示每个频率的 Amplitude 或强度。颜色越亮,信号的能量越高。频谱图的每个垂直 “切片” 本质上是该时刻信号的频谱,并显示信号强度在该时刻信号中的每个频率中的分布情况。
在下面的示例中,第一张图片显示了时域中的信号,即。振幅与时间的关系。它让我们了解剪辑在任何时间点的响度或安静度,但它为我们提供的关于存在哪些频率的信息非常少。
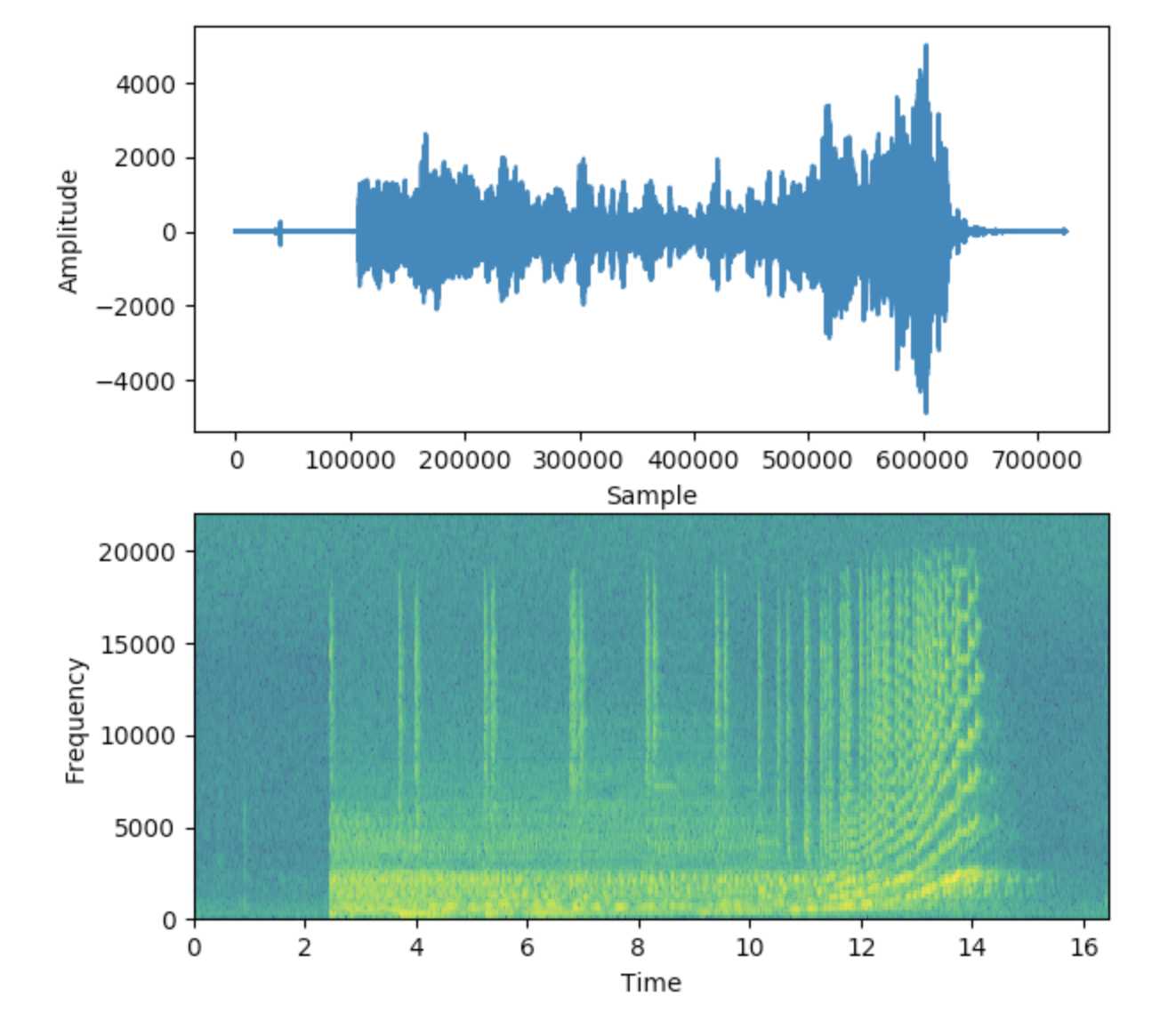
第二张是频谱图,在频域中显示信号。
生成频谱图
频谱图是使用傅里叶变换生成的,用于将任何信号分解为其组成频率。尽管已经忘记了学过的关于傅立叶变换的东西也没事,伟大的python提供了豪用的库函数可以直接使用,这样我们只要写一步就能生成频谱图了。
音频深度学习模型
现在我们知道了频谱图类似于音频的“指纹”,是将音频捕获为图片的一种优雅的方式。
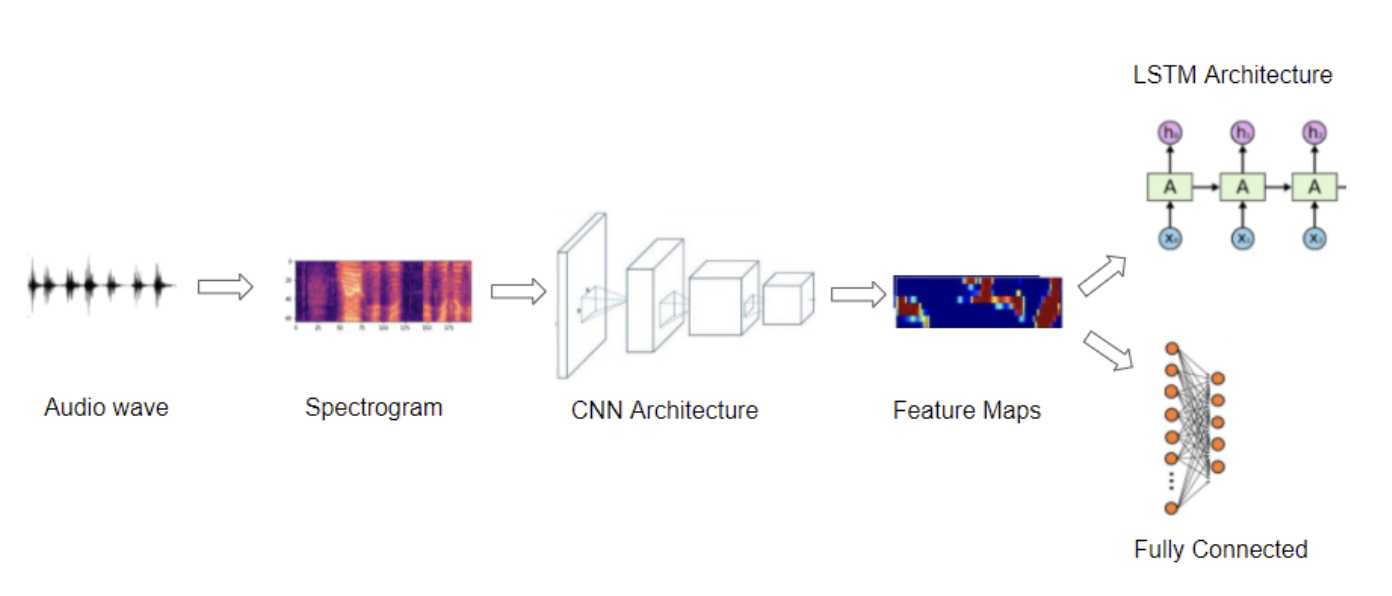
上面是通过CNN进行音频深度学习的模型图。
因此大多数深度学习音频的应用程序都使用频谱图来表示音频。通常遵循以下步骤:
1.从wave文件形式的原始音频开始。
2.将音频数据转化为频谱题。
3.用一些简单技术增强频谱图数据或者直接增强音频数据。
4.用标准的 CNN 架构来处理它们并提取特征图,这些特征图是频谱图图像的编码表示
从此编码表示形式生成输出预测
1.对于音频分类问题,可以通过通常由一些完全连接的 Linear 层组成的 Classifier 来传递它。
2.对于 Speech-to-Text 问题,可以将其传递一些 RNN 层,以从此编码表示中提取文本句子。

我只承认爱莉希雅小姐美丽无双